Sitemap.xml × klasická mapa webu
Existují dva typy sitemap. Kromě souboru sitemap.xml, o kterém je tento článek, je to ještě tzv. mapa webu, obvykle odkazovaná z patičky každé stránky. Lidem se to často plete. Čím se tedy liší?
Mapa webu je obvykle klasická HTML stránka v designu ostatních běžných stránek na webu. Vypisujeme sem odkazy na nejdůležitější stránky webu. Nebo je sem automaticky generuje redakční systém. U opravdu rozsáhlých webů zde nemusí být všechny stránky, stačí odkazy na hlavní sekce. Pro představu se můžete se mrknout na mapu tohoto webu.
Všimněte si, že odkazy sem vypisujeme hierarchicky. To proto, že mapa webu slouží především návštěvníkům stránek – je to vlastně určitý druh navigace. Společně s hlavní a drobečkovou navigací lidem ukazují, jak je web přesně strukturovaný a co zajímavého zde ještě na návštěvníky čeká.
E-book za mail
Získejte podrobný návod Jak na e-mail marketing (52 stran). Více informací.
Žádný spam, jen užitečný obsah. Newsletter posílám cca 8× ročně. Odhlásíte se kdykoliv.
K čemu slouží sitemap.xml
Soubor sitemap.xml proti tomu slouží především vyhledávačům. Pokud bychom na webu sitemap.xml neměli, vyhledávač by musel procházet web stránku po stránce, přecházet mezi nimi pomocí jednotlivých odkazů a nový obsah takto hledat postupně. To může být u většího webu značně zdlouhavé. A může se také stát, že robot vyčerpá přidělený crawl budget dříve, než nový obsah vůbec objeví.
Naproti tomu XML sitemap to crawlerovi velmi zjednodušuje. Stačí mu, když si ze souboru přečte seznam všech stránek webu najednou a porovná ho s těmi, o kterých už ví z dřívějších návštěv. K novému či aktualizovanému obsahu se tak dostane mnohem rychleji.
Jaké weby potřebují sitemapu
XML sitemap není na webu povinná. Může však hodně pomoci s procházením webu a tím i s jeho indexací. Zejména se hodí pro následující typy webů:
-
Nové weby
Jestliže web vznikl nedávno a nevede na něj dosud mnoho zpětných odkazů, ochota vyhledávače web procházet je hodně malá. Sitemap.xml mu však všechny stránky předloží najednou, vyhledávač je tedy spíše zanidexuje a tím pak odkazy snáze získáme.
-
Velké weby
Je-li web rozsáhlý, zvyšuje se pravděpodobnost, že robot prochází stále stejné části a je pro něj těžší objevit nový obsah, který je zastrčený někde v hloubce. Říká se, že sitemapa se vyplatí, pokud má web více než 500 indexovatelných stránek.
-
Weby s horším vnitřním prolinkováním
Na některých webech existuje obsah, na který nevede žádný odkaz. Takovým stránkám říkají SEO konzultanti sirotčí (orphan page). A nevede-li na stránku žádný odkaz, bez sitemapy ji samozřejmě vyhledávač nedokáže najít.
-
Weby, kde rychle přibývá čerstvý obsah
Na mysli mám obsah, který je hodně hledaný, dokud je čertvý – a po několika dnech už rychle zapadne. Typické je to pro zpravodajské weby, které se snaží zobrazovat se v Google News.
-
Weby bohaté na média
Pokud váš web obsahuje spoustu obrázků či videí, která byste rádi dostali do vyhledávání obrázků a videí, určitě využijete speciální typy sitemap, o kterých píšu níže.
Základní formát souboru sitemap.xml
Takto vypadá nejmenší možný kód XML sitemapy, obsahující všechny povinné položky. Vidíte, že struktura je velmi jednoduchá:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://www.strafelda.cz/sitemap-xml</loc>
</url>
</urlset>
Ukázku kódu si trochu rozklíčujeme:
- Na začátku souboru zapisujeme řádek s definici XML, ve které zároveň uvedeme kódování souboru. To by mělo být vždy pouze
UTF-8. - Následuje párový element
<urlset>, který nese atributxmlns. Ten se odkazuje na dokumentaci sitemap. - Dovnitř setu URL už se pak zapisují jednotlivé adresy. Každou z nich zapisujeme v absolutní podobě do párového elementu
<url>, do kterého ještě zanoříme párový element<loc>(zkratka z location). Na pozici konkrétní URL v sitemapě nezáleží, vyhledávač by měl najít všechny bez ohledu na řazení.
Rozšířené definice jednotlivých adres
Kromě samotné adresy stránky můžeme podle dokumentace vyhledávači předat i další nepovinné informace. Ty zapisujeme zapisujeme jako další řádky do elementu <url>:
<url>
<loc>https://www.strafelda.cz/sitemap-xml</loc>
<lastmod>2022-05-04</lastmod>
<changefreq>monthly</changefreq>
<priority>0.5</priority>
</url>
Lastmod
Do elementu <lastmod> uvádíme datum poslední úpravy stránky. Datum může být zapsáno v ISO formátu YYYY-MM-DD, nebo jako W3C datetime (i s uvedením přesného času).
Google se datem poslední modifikace řídí, pokud zjistí, že tam web generuje pravdivá data (tj. opakovaně si ověří, že stránka byla změněna a změna odpovídá datu uvedenému v sitemapě).
Changefreq
Párový element <changefreq>, kam uvádíme, s jakou frekvencí se stránka mění. Možné hodnoty jsou always, hourly, daily, weekly, monthly, yearly a never.
Doporučuji se frekvencí (a stejně tak i prioritou) příliš nezabývat. Jednak jsou to jen doporučení, kterými se vyhledávač vůbec nemusí řídit. A Google dokonce oficiálně ve svých doporučeních pro webmastery prohlašuje, že tyto elementy v XML sitemapách úplně ignoruje.
Priority
Do párového elementu <priority> uvádíme, jak vysokou má naše stránka prioritu ve srovnání s ostatními stránkami našeho webu. Hodnoty se pohybují mezi 0.0 a 1.0. Výchozí hodnota je 0.5. Pokud tedy má mít priorita nějakou vypovídací hodnotu, měla by se pro různá adresy lišit (jestliže všem adresám nastavíme 1.0, nic to vlastně vyhledávači neříká).
Alternativní formáty sitemap
Jen pro doplnění uvedu, že Google podporuje kromě souborů XML i další formáty sitemap.
Textová sitemapa
Tato sitemapa je vlastně jednoduchý textový soubor, kde každou adresu stránky uvedeme na jednu řádku. Soubor pojmenujeme sitemap.txt a měl by být také kódovaný pomocí kódování UTF-8.
Feedy ve formátu RSS 2.0 a Atom 1.0
RSS feedy obvykle generují různé blogovací platformy, proto je Google také podporuje. Problém je však v tom, že RSS kanál obvykle obsahuje jen několik desítek posledních příspěvků, nikoliv odkazy na všechny důležité stránky. Máte-li tu možnost, je tedy určitě lepší využít klasický soubor sitemap.xml.
Jaké adresy do sitemapy předávat
Do sitemap.xml přidáváme všechny stránky, které na webu existují, fungují a u kterých si přejeme, aby se o nich vyhledávač dozvěděl a zaindexoval je. Tedy:
-
Stránka by měla vracet kód 200
Stavový kód 200 říká, že stránka existuje, na rozdíl třeba od kódu 404 – stránka neexistuje), nebo 301 – stránka je přesměrovaná.
-
Stránka by neměla mít zakázané procházení
Je-li stránka zakázaná v souboru robots.txt, robot se o ní sice ze sitemap.xml dozví, ale nesmí se na ni pak jít podívat. Takže vám to pak celé vůbec k ničemu není.
-
Stránka by neměla mít zakázanou indexaci
Stránky umisťované do sitemap.xml by neměly nést meta tag robots s hodnotou
noindex. A neměly by také vracet HTTP hlavičku X-Robots-Tag s hodnotounoindex.Výjimkou z toho pravidla jsou stránky, které již byly dříve zaindexovány a my je nově chceme z indexu vyhodit – pak je úmyslně určitou dobu v sitemapě necháváme, aby se urychlila návštěva robota a ten změnu zjistil.
-
Stránka by neměla být kanonickou duplicitou
Pokud stránka obsahuje canonical tag s hodnotou jinou, než je adresa stránky, do sitemap.xml ji nepřidáváme.
-
Stránka má rozumnou životnost
Pokud víme, že stránka bude existovat jen pár dní (typicky třeba stránka obsahující nějaký inzerát), je obvykle lepší ji do XML sitemapy vůbec nedávat.
-
Stránka není zamčená pod heslem
Do XML sitemapy pochopitelně patří jen stránky, na které se člověk poté z vyhledávače dostane. Pokud je stránka zamčená, vyhledávač ji indexovat nebude, i když ji do sitemapy přidáte. Výjimkou jsou stránky, kde je zamčený jen kus obsahu (třeba poslední dvě třetiny), tam může mít jejich přidání do sitemap.xml smysl.
Sitemap index
Každý soubor sitemap.xml by měl splňovat následující pravidla:
- maximálně 50 000 adres
- maximálně 50 MB (v nekomprimované podobě)
Větší sitemapy je proto třeba rozdělit do více souborů a vytvořit jejich index. Ten vypadá takto:
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>http://www.strafelda.cz/sitemap.xml</loc>
</sitemap>
</sitemapindex>
V ukázce kódu vidíme:
- Definici XML, stejnou jako u sitemap.xml. V ní opět uvádíme kódování souboru, které bybýt vždy pouze
UTF-8. - Párový element
<sitemapindex>, který obsahuje atributxmlnsodkazující se na dokumentaci sitemap. - Dovnitř sitemapindexu už pak pro každou sitemapu zapisujeme párový atribut
<sitemap>, ve kterém je opět párový atribut<loc>obsahující absolutní adresu dané sitemapy.
Best practice k rozdělování sitemap
Tahle pravidla využijete jen u opravdu velkých webů a e-shopů:
- Oficiální limit je sice 50 000 adres na jednu sitemapu, lepší je však vytvořit více menších sitemap, řekněme po 10 000 adresách. Takové se pak rychleji zpracovávají.
- Osvědčuje se sitemapy vytvářet podle typů obsahu (například produkty do jedné, kategorie do druhé, blog do třetí…). Výhodou je, že se pak snáze pro různé typy obsahu sledují statistiky (v Google Search Console).
- Velké sitemapy (a vlastně všechny) se určitě vyplatí gzipovat. Taková sitemapa má buď koncovku
.gz(třebasitemap.xml.gz), nebo posílá hlavičkuContent-Type (application/x-gzip).
Jak sitemapu vytvořit
Pokud používáte některý sofistikovanější redakční systém, pravděpodobně umí generovat sitemap.xml sám od sebe. Zjistěte si více v dokumentaci či u vývojářů.
Pro běžné open source redakční systémy, jako jsou Wordpress, Drupal či Joomla, existují speciální pluginy, které soubor sitemap.xml vytvoří. Pro WordPress se nejčastěji používá plugin Yoast SEO, ve kterém lze nastavit i další užitečná SEO nastavení.
Poslední možností je vytvořit sitemapu ručně. Buď necháte web projít nějakým crawlerem, jako je Xenu, SEO Macroscope nebo placený Screaming Frog. A z jejich výstupů si sitemapu sami připravíte. Nebo využijete některý z online nástrojů.
Jak se vyhledávač o sitemap.xml dozví
Existují hned čtyři způsoby, jak se může vyhledávač o našem souboru sitemap.xml dozvědět.
Dívá se na standardní umístění
Většina webů má sitemapu pojmenovanou sitemap.xml a má ji umístěnou v kořenovém adresáři domény. Takže když se robot vyhledávače podívá sem, sitemapu najde bez jakýchkoliv dalších nápověd:
https://www.strafelda.cz/sitemap.xml
Pomocí souboru robots.txt
V souboru robots.txt můžeme uvést absolutní cestu k sitemapě:
Sitemap: https://www.strafelda.cz/sitemap.xml
Tuto direktivu sem můžeme dokonce uvést až stokrát (samozřejmě s různými adresami) a tím se odkázat až na sto různých sitemap.
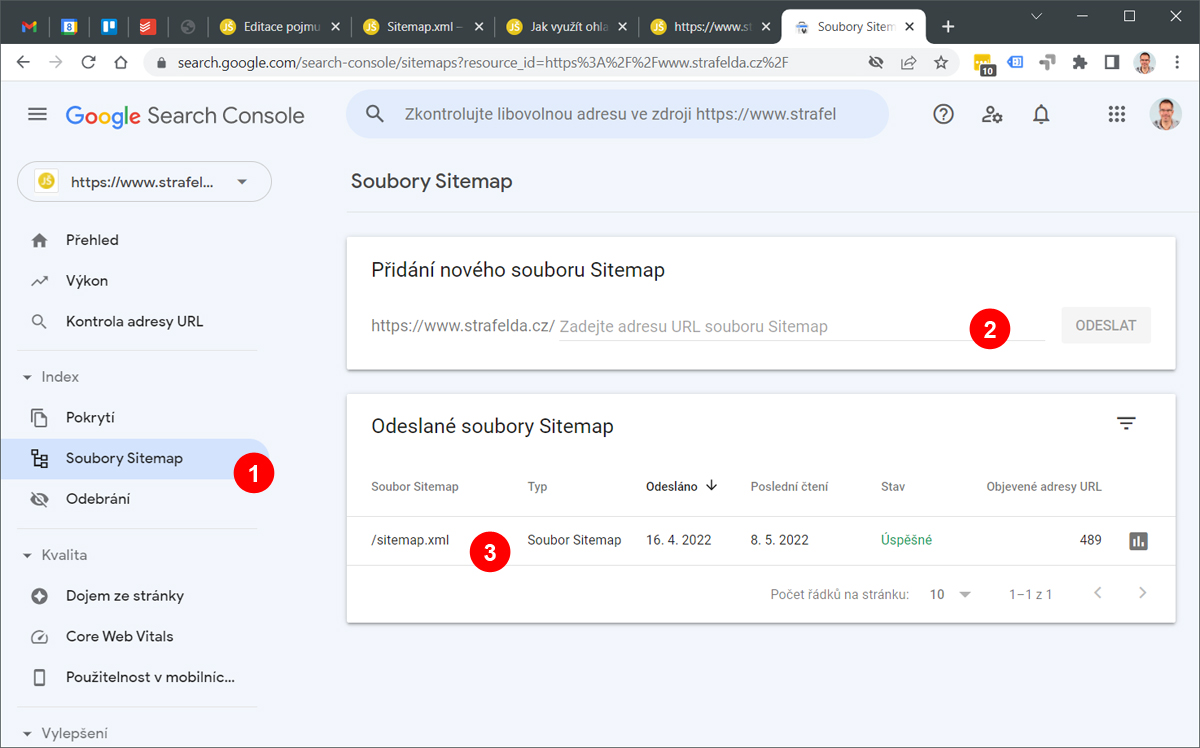
Pomocí Search Console/Seznam Webmaster Tools
Adresu sitemapy můžeme Googlu předat také v nástroji Google Search Console. Stejně tak Seznamu v jeho nástroji Seznam Webmaster Tools.
Pomocí pingnutí
Googlu můžete předat informaci o sitemap.xml úplně jednoduše, stačí zadat do adresního řádku prohlížeče následující adresu (jen zde samozřejmě musíte změnit odkaz na adresu vaší sitemapy):
https://www.google.com/ping?sitemap=https://www.strafelda.cz/sitemap.xml
Speciální typy sitemap
Všechny tyhle sitemapy můžete vytvořit jako samostatný soubor, ale také lze příslušné elementy vložit do klasické sitemapy s adresami stránek a mít tak vše v jediném souboru. Záleží na programátorech, co se jim bude vytvářet snáze. A tom, jestli budete chtít sledovat nějaké statistiky.
Sitemap.xml pro jazykové verze
Tento typ sitemapy se používá podobně jako hreflang, tedy k propojení různých překladů téhož obsahu.
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml">
<url>
<loc>https://www.strafelda.cz/page</loc>
<xhtml:link rel="alternate" hreflang="de" href="https://www.strafelda.de/page"/>
</url>
</urlset>
Z ukázky vidíte, že logika je stejná jako u klasické sitemapy, jen u elementu <urlset> přibyl nový namespace. A do elementu <url> zapisujeme elementy <xhtml:link> s příslušnou jazykovou verzí.
Sitemap.xml pro obrázky
Sitemapa umožňuje odkázat konkrétní obrázky na dané stránce:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:image="http://www.google.com/schemas/sitemap-image/1.1">
<url>
<loc>https://www.strafelda.cz/nazev-stranky</loc>
<image:image>
<image:loc>https://www.strafelda.cz/obrazek-1.jpg</image:loc>
</image:image>
</url>
</urlset>
I zde u elementu <urlset> přibyl nový namespace. A do elementu <url> pak pro každý obrázek přidáváme párový element <image:image> a v něm <image:loc>, kde je uvedena adresa obrázku. Dříve se sem zapisovaly také elementy s titulkem obrázku, informacemi o licenci atd., ale ty již Google nepodporuje.
Sitemap.xml pro videa
Koncept je stejný jako u obrázků, jen namespace se liší a místo elementu <image:image> přidáváme element <video:video>. Ten pak obsahuje spoustu informací o daném videu, jako je adresa, název, popisek, obrázek náhledu, délka a další. Je jich hodně, tak vás pro více informací odkážu rovnou do oficiální nápovědy Google.
Sitemap.xml pro Google News
Speciální XML soubor pro agregátor nejčerstvějších zpráv Google News. Jedna sitemapa mapa může obsahovat až 1 000 zpráv. Ty by však neměly být starší než dva dny, poté je třeba je ze sitemapy smazat.
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:news="http://www.google.com/schemas/sitemap-news/0.9">
<url>
<loc>https://www.strafelda.cz/page</loc>
<news:news>
<news:publication>
<news:name>Název média</news:name>
<news:language>cs</news:language>
</news:publication>
<news:publication_date>2022-05-11</news:publication_date>
<news:title>Název článku</news:title>
</news:news>
</url>
</urlset>
Nejčastější dotazy k pojmu Sitemap.xml
01 Bude vadit, když soubor sitemap.xml pojmenujeme jinak?
Nebude. Pojmenování sitemap.xml je jen konvence. Ale pokud v robots.txt uvedete odkaz na jiný soubor ve správném formátu, nebo ho přidáte přes Search Consoli či Seznam Webmaster Tools, bude vám to také fungovat.
02 Musí být sitemap.xml umístěný v kořenovém adresáři domény?
Není to povinné. Záleží na tom, jakou adresu souboru sitempa.xml předáte vyhledávači v souboru robots.txt a Search Consoli/Seznam Webmaster Tools. Nicméně, pokud k tomu nemáme žádný pádný důvod, obvyklé umístění sitemapy neměňte.
03 Máme v sitemapě desetitisíce stránek a našemu CMS docela trvá, než sitemap.xml vygeneruje. Vadí to?
Trochu to vadí, protože při čekání na sitemapu zbytečně čerpáte čas, který má robot vyhledávače na váš web přidělený. Osvědčené řešení spočívá v tom, že sitemapu vygenerujeme jako statický soubor a přegenerováváme ji pokaždé, když se na některé stránce webu něco změní. Robot vyhledávače pak tedy na generování nečeká.
04 Může se stát, že Google sníží hodnocení již zaindexovaným stránkám, které nemáme v sitemap.xml?
Nemůže. XML sitemap je jen jednoduchý nástroj, kterým můžete vyhledávač o existenci stránek informovat. A jestli je pak zaindexuje, to už je na něm. A stejně tak stránku nevyhodí z indexu jen proto, že ji v sitemapě nemáte. Otázkou však samozřejmě zůstává, proč ji do sitempa.xml nepromítáte.
05 Máme v sitemap.xml stránky, které jsou funkční, mají povolenou indexaci a nejsou kanonizované. Stejně nám je však Google neindexuje. Co s tím?
Takto se Google obvykle chová u stránek, které jsou nové – už o nich ví, ale ještě je nestihl zaindexovat. Nebo pro něj obsah stránky není zajímavý (je moc krátký, duplicitní apod.) a indexovat je vůbec nechce. Pokud nejde ani o jeden z těchto případů, obvykle pomáhá na danou stránku získat více odkazů, vnitřních i zpětných.
06 Změnili jsme svůj ručně generovaný soubor sitemap.xml. Máme jej znovu přidat v Search Console?
Ne, jednou přidanou mapu už znovu do Google Search Console nepřidávejte. Google změnu sám zjistí při příští návštěvě crawlera na vašem webu.
Stručně z historie sitemap.xml
Jen pro zajímavost, jak je vlastně protokol starý:
- Červen 2005 – Google představil první verzi protokolu sitemap.xml.
- Listopad 2006 – k podpoře sitemap v XML formátu se přidalo Yahoo! a Microsoft.
- Duben 2007 – k podpoře protokolu sitemap.xml se přidal vyhledávač Ask.com. Google, Yahoo! a MSN ohlásili, že budou automaticky načítat odkaz na soubor sitemap.xml ze souboru robots.txt.
Další užitečné odkazy
- Sitemaps XML – oficiální specifikace pro soubory sitemap.xml (anglicky).
- Nápověda Google k sitemapám (anglicky).
- XML Sitemap Validator – ověřte si správnost syntaxe své sitemapy pomocí jednoduchého nástroje zdarma.